
ChatGPT: A cautionary
tale in cost-effectiveness modelling
Our viewpoint
24 August 2023


In recent months, many of us have been navigating the unchartered waters of large language models such as ChatGPT to understand how they may be able to support us with both personal and professional tasks.
Here, Nishit Dhanji (Health Economist) and Catrin Treharne (Health Economics Lead), share their reflections on recent conversations with ChatGPT to shed some light on where it may be able to help in cost-effectiveness model conceptualisation, and where it is more likely to hinder the process.
Good first impressions
Can ChatGPT answer fundamental health economics questions? It offered textbook-like responses to questions ranging from 'How would you conduct a cost-effectiveness analysis?' to 'Why is a decision-analytic model necessary? The depth of information provided was impressive (see Worked example 1).
Worked example 1

Tip: Asking for examples is a good way to gain a better understanding of the responses provided by ChatGPT.
Moving on to something more specific, we posed questions about conceptualising a cost-effectiveness (CE) model for a novel Alzheimer's drug, and gave ChatGPT a link to the clinicaltrial.gov website for an example product so it could extract relevant details (see Worked example 2).
Worked example 2

Tip: Give ChatGPT a clear brief and share supporting information where confidentiality is not a concern. Plugins are currently an effective way to enhance ChatGPT’s functionality. In this example we used the ‘BrowserOP’ plugin to enable ChatGPT to query the ClinicalTrials.gov website.
ChatGPT gave a reasonable response, suggesting a lifetime Markov model with health states defined by AD severity and broadly aligned with the Institute for Clinical and Economic Review (ICER) model. It gave some high-level considerations of how to use the trial data but initially without any detail of how this would work in practice.
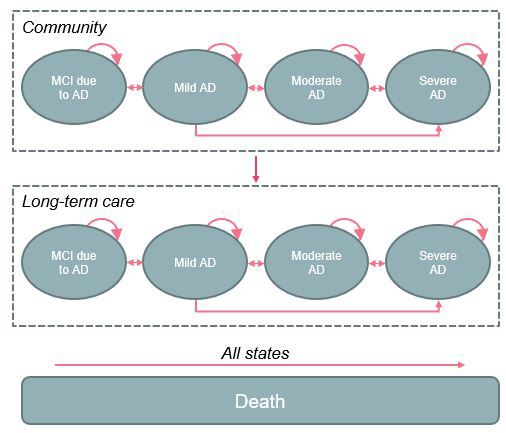
When asked to draw a model diagram using the ‘Show Me Diagrams’ plugin, the limitations of ChatGPT’s proposal became apparent, namely the omission of many realistic transitions, including remaining in a health state from one cycle to the next and transitions between non-adjacent health states. The proposal also omitted the granularity of ICER’s model, which included health states reflecting patients’ care setting (community or long-term care), accounting for variations in costs, and patient and caregiver quality of life. The two model schematics are shown in Figure 1.
Figure 1. ICER vs ChatGPT model structures
|
ICER Model |
ChatGPT Model* |
 |
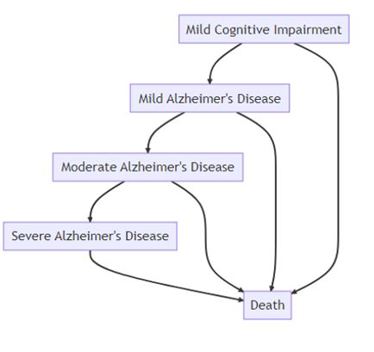 |
*Developed using the ChatGPT ‘Show Me Diagrams’ plugin. Abbreviations: AD, Alzheimer’s disease; ICER, Institute for Clinical and Economic Review; MCI, mild cognitive impairment.
Diving deeper into one of the most important aspects of economic evaluation, the choice of relevant comparators, ChatGPT was a helpful sounding board. When asked to suggest comparators for the analysis, it initially explained that the model’s comparators should reflect standard of care in the market of interest. With the UK as an example market, it quoted correctly from NICE guideline NG97, suggesting that the latest NICE recommendations and clinical guidelines should be reviewed for completeness, and that consultation with clinical experts would be worthwhile as well as potential analysis of real-world data. In terms of identifying treatments of potential future relevance for the analysis, ChatGPT recommended several sources of up-to-date information, including clinical trial databases, industry conferences, and clinical expert input (see Worked example 3).
Worked example 3

Tip: Follow up with clear and concise questions to get more detailed answers. For example, a natural follow-up question for the above example would be to ask ChatGPT to name potential future comparators for the UK market and to cite its sources.
But there are reasons why ChatGPT can’t take over model conceptualisation
One of the biggest issues with ChatGPT is its ability to fabricate information and sources, which is highlighted by the warning message seen underneath its search bar. ChatGPT’s propensity to ‘hallucinate’ has been well documented[1]. While it did provide many useful and accurate references to both books and published papers, ChatGPT also invented credible-sounding papers by authors who have published extensively in economic evaluation in AD.
Fabrication of information didn’t stop at references. ChatGPT also invented content when a PDF plugin was used to evaluate a cost-effectiveness study using the CHEERS checklist, as well as when asked to summarise information from the NICE website, suggesting that it does not yet represent a viable solution for the literature review component of model conceptualisation.
ChatGPT was expected to be able to explain mathematical concepts correctly. Given that its training is based on sources that would typically be on the desk (or desktop) of every health economist, surprisingly ChatGPT committed the cardinal sin of equating rates with probabilities by suggesting modifying the baseline transition probability by a hazard ratio. Clearly, ChatGPT has managed to skip the go-to “Summary of the distinction between rates and probabilities” in Briggs et al’s 2006 health economics bible[2] during its training.
Finally, when asked to assume the role of an AD clinical expert with varying years of experience, ChatGPT did adopt this persona, but quickly explained that it is not in fact a neurologist therefore its responses would be based on its training data (see Worked example 4).
Worked example 4

Tip: Engaging in role-playing with ChatGPT can be an effective way to receive response from a different viewpoint but is no substitute for a conversation with a human with lived experience.
Final reflections
At first glance, ChatGPT appears to be the perfect partner for model conceptualisation and this exercise generated many examples of it providing sound health economic guidance. However, dig beneath the surface and the risk of inaccurate and/or incomplete information quickly becomes apparent. Its ability to invent information and provide flawed instructions is worrying and ultimately undermines its dependability.
In its current form, ChatGPT’s role in model conceptualisation is therefore fairly limited. Plenty of flaws emerged in this exercise, even though ChatGPT was being tested on a disease area where its training data should be plentiful. Where published literature is scarce or non-existent, for instance with a rare disease, ChatGPT would have even greater difficulty. However, there is no doubting its potential, as long as users remain aware of the problems and limitations.
At LCP Health Analytics we are committed to staying at the forefront of developments in AI in its many forms. Please reach out to us to discuss this blog’s findings and to explore how we can support you with your modelling needs.
[1] Weise, Karen, and Cade Metz. ‘When A.I. Chatbots Hallucinate’. The New York Times, 1 May 2023, sec. Business. https://www.nytimes.com/2023/05/01/business/ai-chatbots-hallucination.html
[2] Briggs, A.H., Claxton, K. & Sculpher, M.J. 2006, Decision modelling for health economic evaluation, Oxford University Press, Oxford. Decision Modelling for Health Economic Evaluation — Health Economics Research Centre (HERC) (ox.ac.uk)